
找对业务G点, 体验酸爽 - PostgreSQL内核扩展指南
背景
通用数据库就像带装修的房子一样,如果按数据库的功能划分,可以分为豪华装修、精装、简装。
PostgreSQL从SQL兼容性、功能、性能、稳定性等方面综合评价的话,绝对算得上豪华装修级别的,用户拎包入住就可以。
不过通用的毕竟是通用的,如果G点不对的话,再豪华的装修你也爽不起来,这是很多通用数据库的弊病,但是今天PostgreSQL数据库会彻底颠覆你对通用数据库的看法。
基于PostgreSQL打造最好用的私人订制数据库
花了2个通宵,写了一份PostgreSQL内核扩展指南,时间有限,内容以入门为主。
希望更多人对PostgreSQL内核扩展有个初步的了解,内核扩展并不需要对数据库内核有非常深的了解,用户只要把重点放在业务上,利用PostgreSQL开放的API实现对数据库内核能力的扩展,打造属于自己的数据库。
为什么要扩展数据库功能
在回答这个问题前,我们先回答这个问题。
数据库是不是存数据就可以了?所有的运算都交给应用程序来?
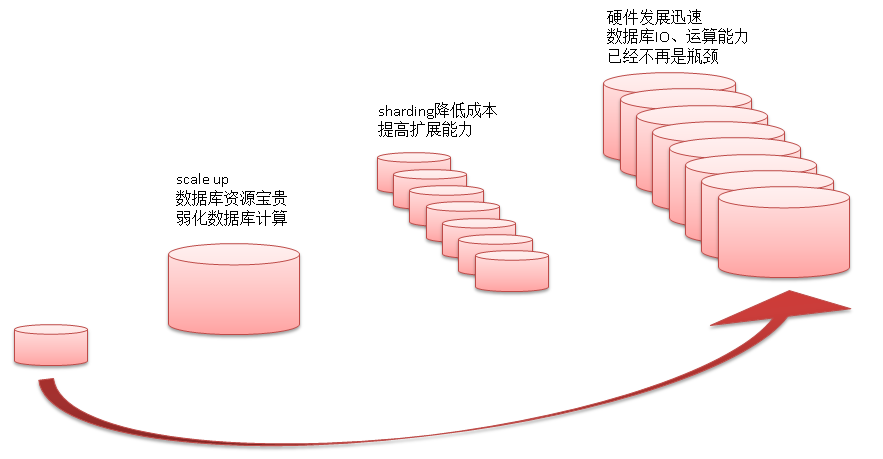
在数据大集中、硬件成本高的年代。在较为general的硬件条件下,为了避免数据库的计算成为瓶颈你可能会这样做,把数据库用得尽量简单,几乎不做任何的运算,只做简单的增删改查。
随着数据库技术的发展,水平分库被越来越多的得到应用。同时硬件也在不断的发展,CPU核数、内存带宽、块设备的带宽和IOPS的发展都很迅猛。甚至GPU辅助运算也开始逐渐成为加速的焦点。
数据库的所依托的硬件运算能力已经非常强大,这种情况下只把数据库用作简单的数据存取会带来什么问题呢?
我之前写过一篇《论云数据库编程能力的重要性》,可以读一下,也许能找到以上问题的灵感。
https://yq.aliyun.com/articles/38377
伴随硬件的飞速发展,叠加数据库的分片技术的发展,现如今使用general硬件的数据库也不再是瓶颈。
对于OLTP的query,数据库往往可以做到us级响应,而在网络层可能要花上毫秒级的时间。业务逻辑越复杂,与数据库交互的次数越多,网络RT会成倍的放大,影响用户的体验。
逻辑更复杂一些的场景,需要将数据取到应用端,在应用端处理,这会涉及到move data,也会较大程度的放大网络RT。move data的模式正在逐渐成为影响用户体验、效率,浪费成本的罪魁祸首。
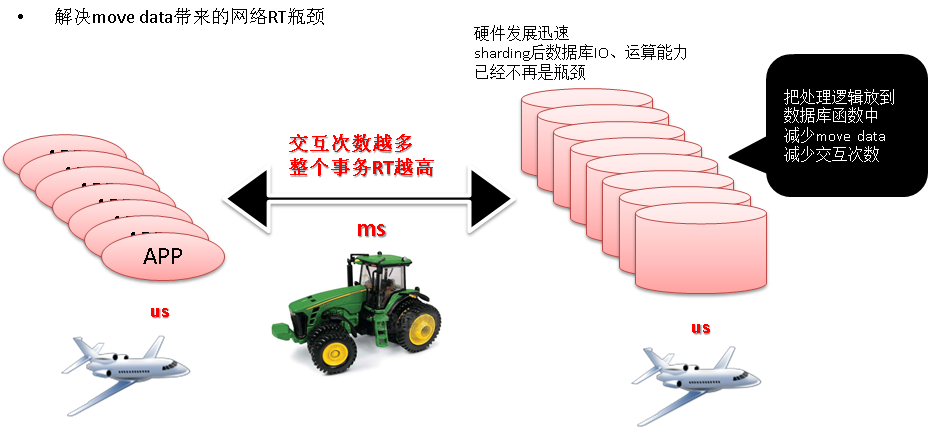
如果能把数据库打造成为同事具备数据存储、管理与处理能力为一体的产品。在数据库硬件资源充足的情况下,把一些数据库能处理的逻辑交给数据库处理,将极大的降低延迟,在高并发低延迟的应用场景非常有效。
这考验的就是数据库的扩展能力。
为什么PostgreSQL特别适合做内核扩展
我提炼了3点适合做内核扩展的理由,有遗漏的话尽量来补充啊,谢谢。
.1. 接口丰富
PostgreSQL有哪些开放接口?
UDF(可以扩展 聚合、窗口以及普通 的函数)
https://www.postgresql.org/docs/9.5/static/xfunc-c.html
GiST, SP-GiST, GIN, BRIN 通用索引接口,允许针对任意类型自定义索引
https://www.postgresql.org/docs/9.5/static/gist.html
… …
允许自定义扩展索引接口 (bloom例子)
https://www.postgresql.org/docs/9.6/static/bloom.html
https://www.postgresql.org/docs/9.6/static/xindex.html
操作符,允许针对类型,创建对应的操作符
https://www.postgresql.org/docs/9.5/static/sql-createoperator.html
自定义数据类型
https://www.postgresql.org/docs/9.5/static/sql-createtype.html
FDW,外部数据源接口,可以把外部数据源当成本地表使用
https://www.postgresql.org/docs/9.5/static/fdwhandler.html
函数语言 handler,可以集成任意高级语言,作为数据库服务端的函数语言(例如java, python, swift, lua, ……)
https://www.postgresql.org/docs/9.5/static/plhandler.html
动态fork 进程,动态创建共享内存段.
https://www.postgresql.org/docs/9.5/static/bgworker.html
table sampling method, 可以自定义数据采样方法,例如创建测试环境,根据用户的需求定义采样方法。
https://www.postgresql.org/docs/9.5/static/tablesample-method.html
custom scan provider,允许自定义扫描方法,扩展原有的全表扫描,索引扫描等。(例如GPU计算单元可以通过DMA直接访问块设备,绕过USER SPACE,极大的提高传输吞吐率)
https://www.postgresql.org/docs/9.5/static/custom-scan.html
自定义REDO日志encode,decode接口,例如可以用它打造黑洞数据库
https://www.postgresql.org/docs/9.6/static/generic-wal.html
用户可以利用这些接口,打造适合业务的私人订制的数据库。来适配各种特殊场景的需求。
关键是你不需要了解数据库内部的实现,只需要使用这些扩展接口就可以了。
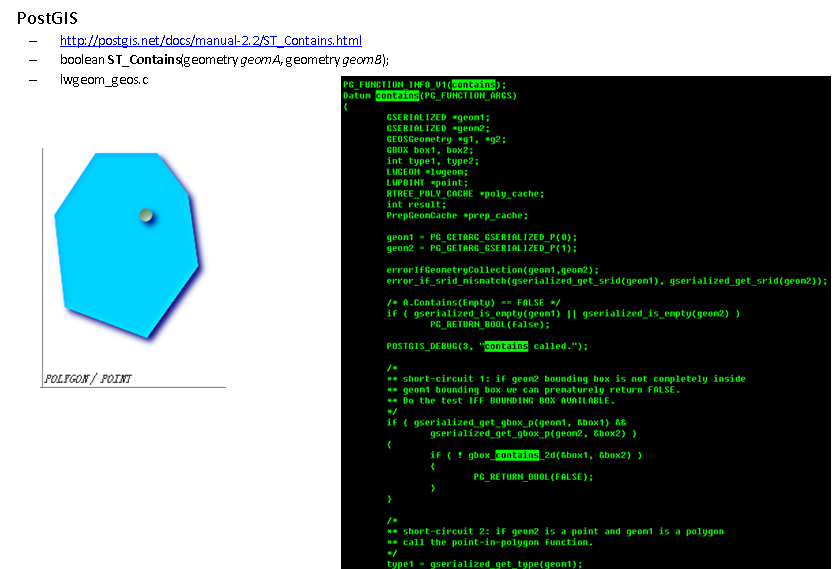
全球使用最广泛的地理位置信息管理系统PostGIS就是通过这种接口扩展的PostgreSQL插件。
(集自定义的数据类型,自定义的操作符,以及在GIN、GiST、SP-GiST、B-tree上开发的索引与一身的插件)
.2. PostgreSQL是进程模式
进程模式也是优势? 必须的。
相比线程模式,多进程相对来讲稳定性较好,一个进程挂掉,重新拉起来就好,但是一个线程crash会导致整个进程都crash。
你肯定不希望给数据库加个功能就把数据库搞挂吧,如果是线程模式,扩展数据库的功能就需要非常谨慎。
而PostgreSQL提供的接口已经有非常多年的历史,通过这些接口开发的插件也是不计其数,接口非常稳定,再加上进程模式,你可以大胆的扩展PostgreSQL的功能。 后面我会给大家看看有哪些不计其数的插件。
.3. BSD许可
擦,BSD许可也是优势? 必须的。
如果你要把你加过功能的PostgreSQL包装成产品售卖,你就会发现BSD的好。 它允许你任意形式分发。
内核扩展指南


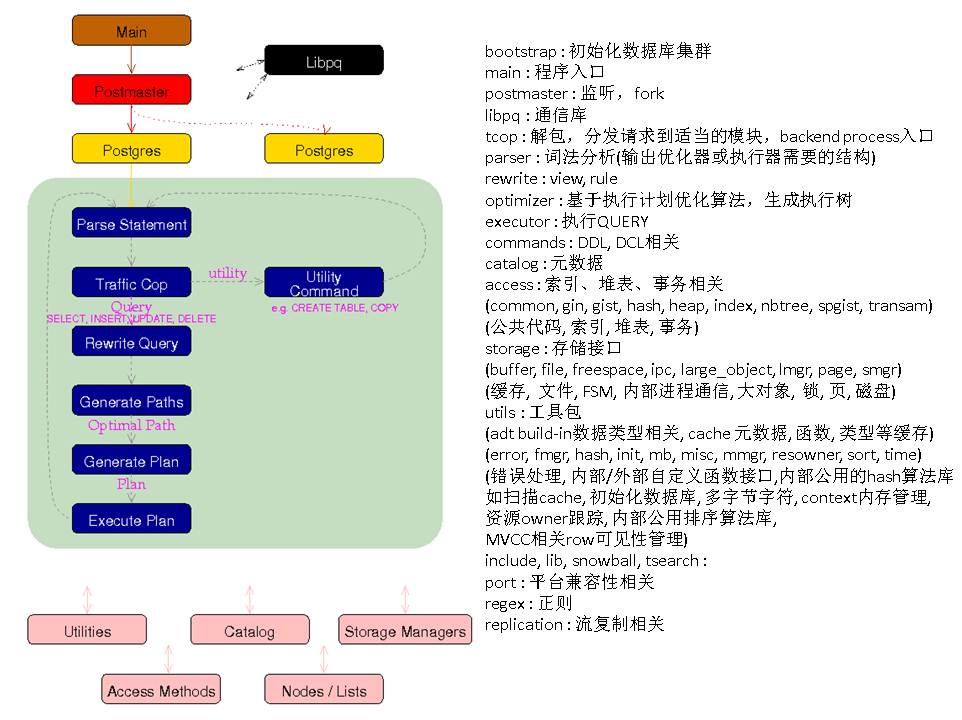
PostgreSQL内核概貌
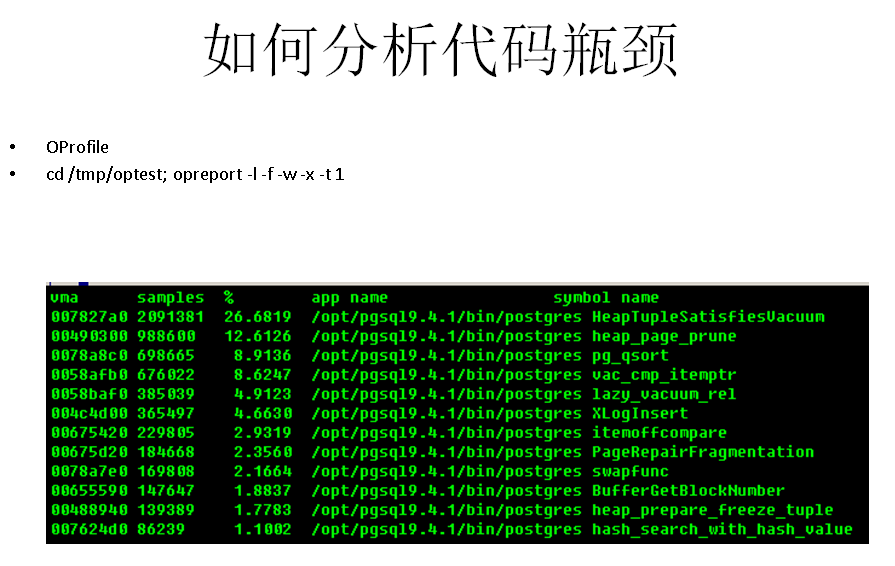
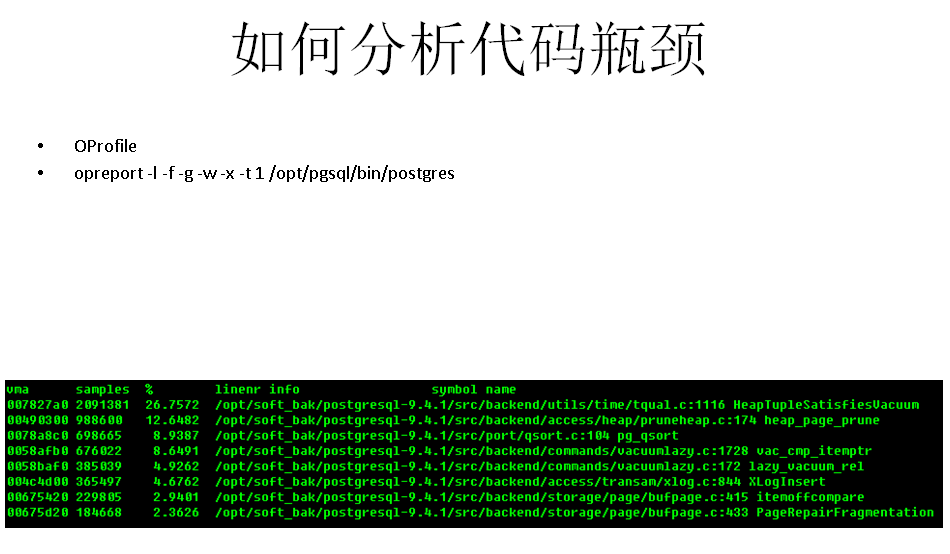
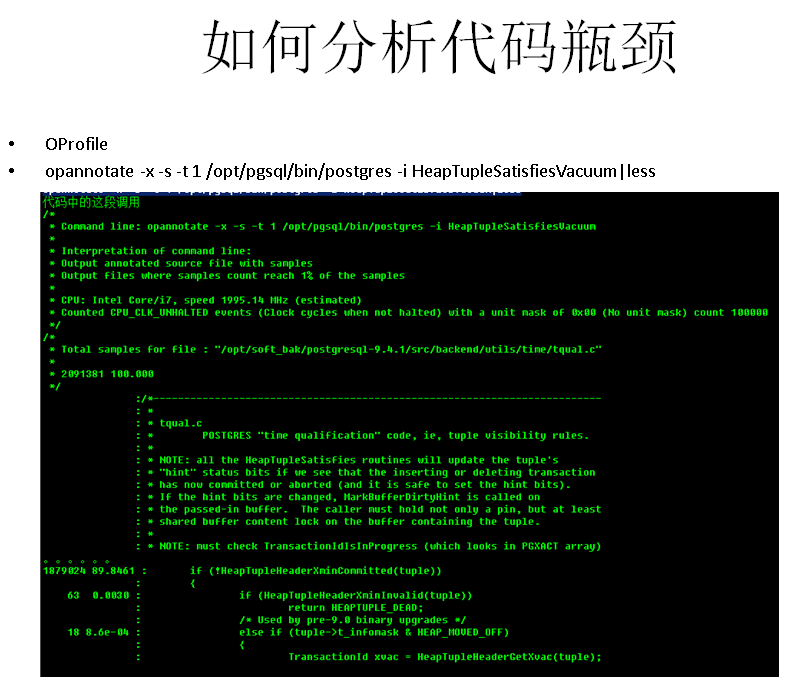
如何分析数据库代码的瓶颈


如何自定义UDF

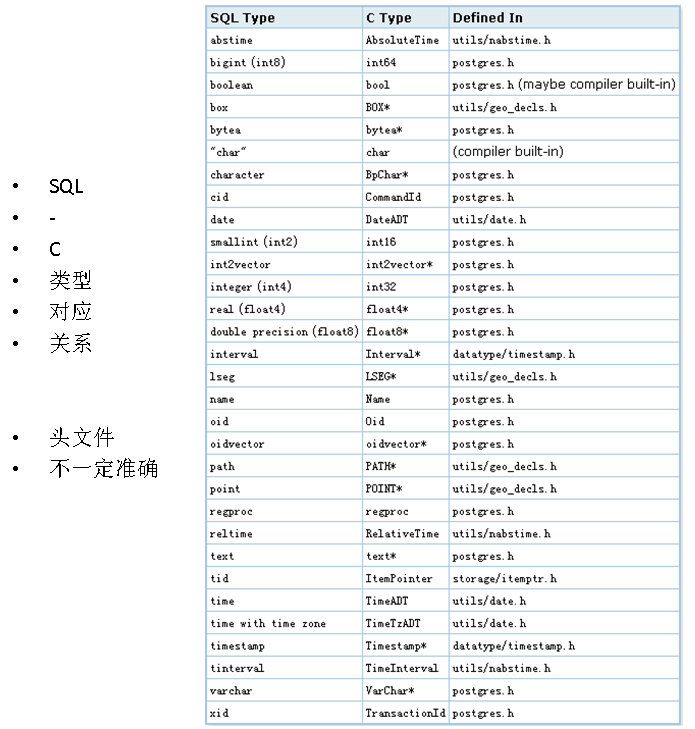
- C类型和SQL类型的对应关系
用户获取SQL参数的宏






用户返回结果给SQL函数的宏




C UDF例子,SQL输入为composite类型

C UDF例子,返回record类型的例子


C UDF例子,返回表(SRF)的例子


C UDF例子,反转字符串的例子


如何编译C FUNC、创建SQL FUNC
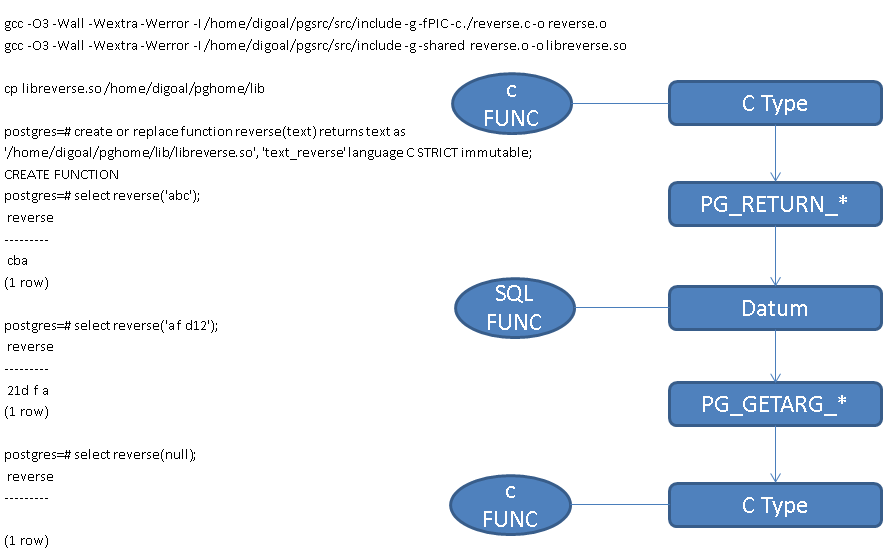
C函数是扩展中最基本的用法,必须掌握。
聚合、窗口、数据类型、操作符、索引,FDW等,都是围绕或者直接基于C FUNC的。
后面你就会理解了,特别是看了语法后,会有更深刻的理解。
聚合函数原理
希望理解好迭代函数,迭代函数的输入参数,初始迭代值,迭代中间结果,以及终结函数,和终结类型。
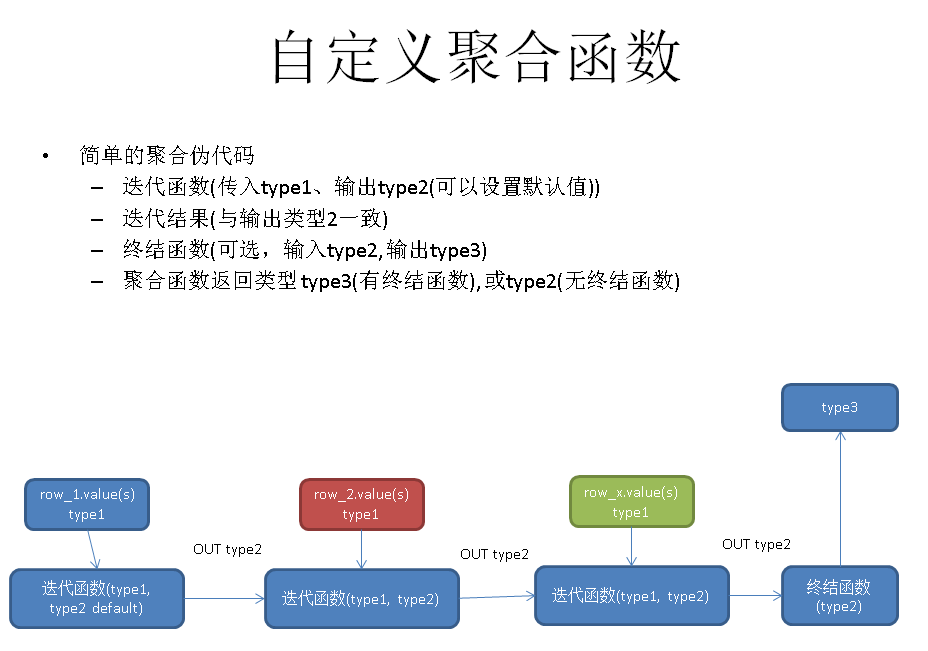
自定义聚合函数

自定义窗口函数

自定义数据类型
数据类型最基本的是输入和输出函数,分别将SQL的text输入转换成C的输入,将C的输出转换成SQL的text。
文本是需要依赖字符编码的,所以PG还支持基于二进制的输入和输出函数,通常可以用来实现数据的逻辑复制,而不需要关心编码的转换问题,所见即所得。



自定义操作符
操作符其实也是函数的抽象,包括操作符的元,操作符的操作数的类型,以及操作符的等价操作符以及反转操作符的定义(被query rewrite用来重写SQL,以适用更多的执行计划选择)
例如: a<>1 等价于 not (a=1),这样的,都是可以互换的。
与操作符相关的,还有优化器相关的OPTION以及JOIN的选择性因子。






自定义操作符例子


自定义索引语法
自定义索引也非常简单,需要实现索引方法中必须的support函数,同时将操作符添加到索引的op class即可。
这些OP就可以用这个索引。

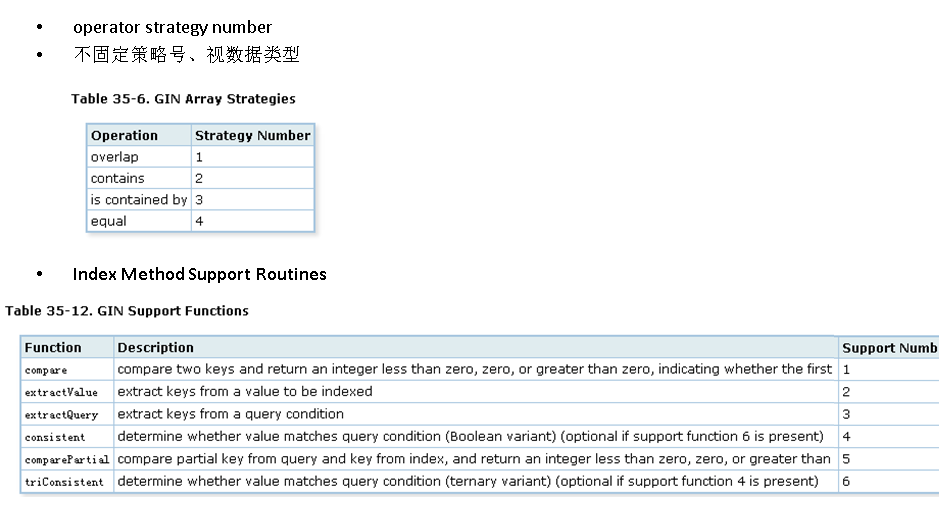
GIN索引接口介绍

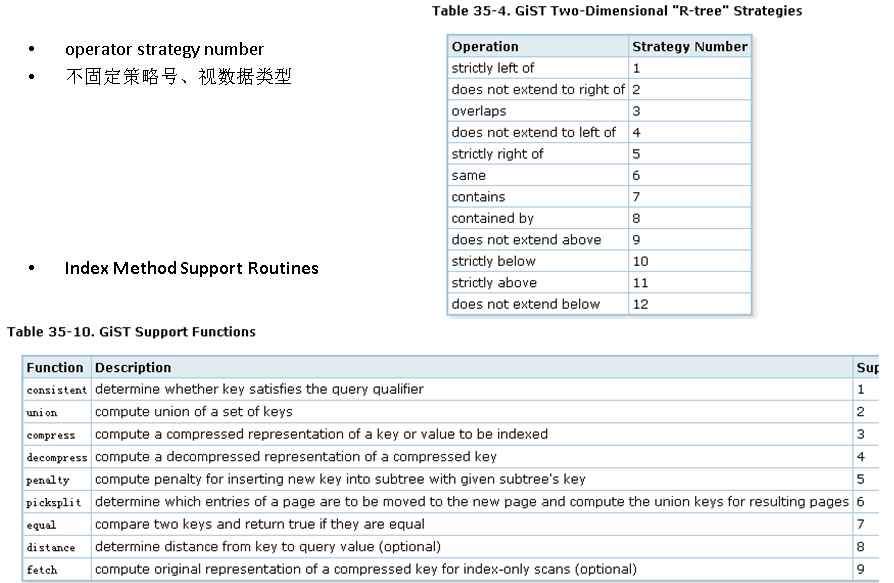
GiST索引接口介绍

SP-GiST 索引接口介绍

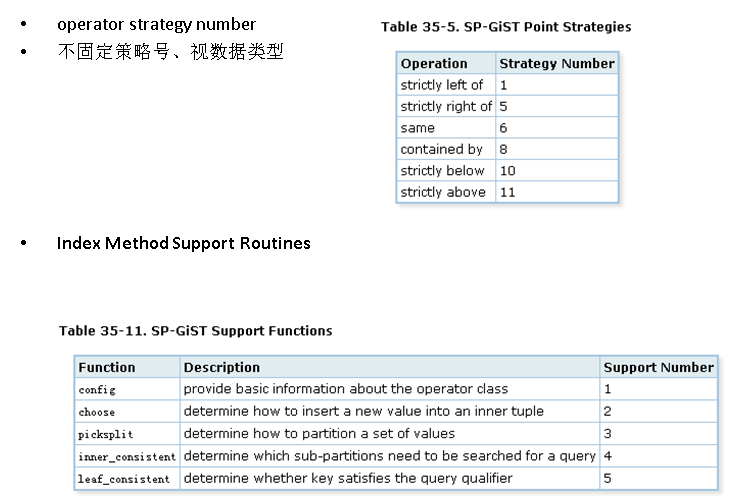
BRIN, BTREE, hash索引接口介绍
gin,gist,sp-gist,brin索引接口的strategy是不固定的,用户可以自行根据索引功能的形态增加。
btree和hash索引接口的strategy是固定的。


自定义GIN索引例子
取自contrib






PostgreSQL 内核扩展接口总结

如何打包与发布PostgreSQL 插件


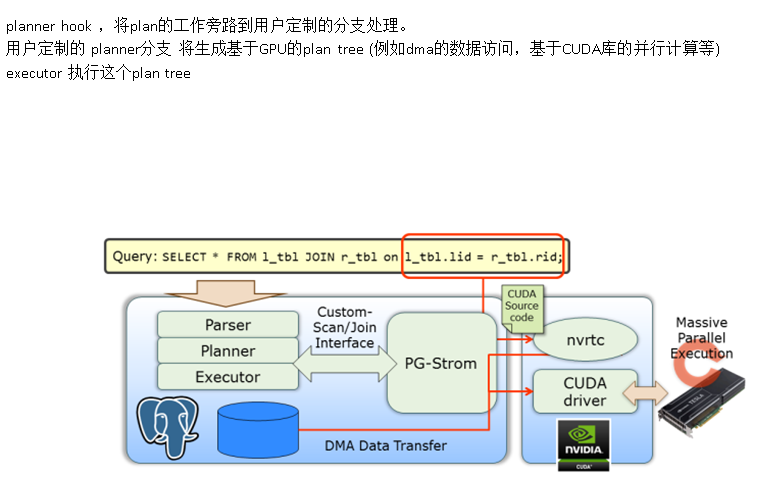
GPU、FPGA如何与PostgreSQL深度整合

PG-Strom介绍

PG-Strom原理介绍
pg-strom利用了planner的hook,在生成执行计划时,使用自定义的执行计划生成器,打造属于自己的执行计划。
同时通过custom scan provider,用户可以使用GPU计算单元使用DMA的方式直接访问块设备,绕过了buffer cache,提升访问吞吐率。
同时自定义计算节点,包括JOIN,排序,分组,计算等,都可以交给GPU来处理。
这样就实现了GPU加速的目的。






GPU加速方向
BULK数据计算。
例如
动态路径规划。
基于BIT运算的人物、人群、企业、小区、城市画像等。
大量数据的文本分析和学习。
动态路径规划

bit逻辑运算


PostGIS点面判断
(笔误,这可能不是gpu的强项,GPU的强项是BULK计算,对延迟没要求,但是对处理能力有要求的场景。)
(点面判断属于OLTP的场景,不需要用到GPU)

除了GPU加速,其实LLVM也是BULK计算的加速方式之一,而且性能非常的棒。
Deepgreen, VitesseDB, Redshift都在使用LLVM技术,加速BULK 计算的场景。
参考资料

扩展举例
PostgreSQL非常适合内核功能扩展,空口无凭。
我给大家列举一些例子。
基因测序插件
https://colab.mpi-bremen.de/wiki/display/pbis/PostBIS
化学类型插件
http://rdkit.org/
指纹类型插件
地理位置信息管理插件
http://postgis.org/
K-V插件: hstore, json
流式数据处理插件
http://www.pipelinedb.com/
时间序列插件
https://github.com/tgres/tgres
近似度匹配: pg_trgm
ES插件
https://github.com/Mikulas/pg-es-fdw
R语言插件
http://www.joeconway.com/plr/
分布式插件
https://github.com/citusdata/citus
列存储插件
https://github.com/citusdata/cstore_fdw
内存表插件
https://github.com/knizhnik/imcs
外部数据源插件
https://wiki.postgresql.org/wiki/Fdw
hll,bloom,等插件
数据挖掘插件
http://madlib.incubator.apache.org/
中文分词插件
https://github.com/jaiminpan/pg_jieba
https://github.com/jaiminpan/pg_scws
cassandra插件
https://github.com/jaiminpan/cassandra2_fdw
阿里云的对象存储插件 oss_fdw
https://yq.aliyun.com/articles/51199
… …
可以找到开源PostgreSQL插件的地方
https://git.postgresql.org/gitweb/
http://pgxn.org/
http://pgfoundry.org/
https://github.com/
http://postgis.org/
http://pgrouting.org/
https://github.com/pgpointcloud/pointcloud
https://github.com/postgrespro
… …
以上都是PostgreSQL非常适合内核扩展的见证。
想像一下可以扩展的行业
图像识别
基于地理位置,O2O的任务调度
电路板检测
脚模
路径规划
透明的冷热数据分离
物联网行业
金融行业
… …
PostgreSQL几乎任何领域都可以深入进去。
小结
1. PostgreSQL 的 进程模式 ,为内核扩展提供了非常靠谱的保障。
2. 你 不需要了解PG内核 是如何编写的,你只需要了解业务,同时使用PG提供的API接口,扩展PG的功能。
3. 几乎所有扩展都是基于 C FUNC 的,所以你务必要掌握好PostgreSQL C FUNC的用法。
4. PostgreSQL有 BSD许可 的优势,在其他开源许可吃过亏的大型企业,现在都非常重视开源许可了。(如果你现在不重视,难道等着养肥了被杀^-^?)
5. PostgreSQL的扩展能力是它的 核心竞争力 之一,好好的利用吧。
一起来打造属于自己的数据库,发挥PostgreSQL的真正实力,开启一个新的数据库时代吧。
欢迎加入阿里云
PostgreSQL、Greenplum、MySQL、Redis、mongoDB、Hadoop、Spark、SQL Server、SAP、… … 只要是你见过的数据库,都有可能在阿里云上相遇。
技术提高生产力,一起为社会创造价值。